CH-SIMS v2.0: A Fine-grained Multi-label Chinese Multimodal Sentiment Analysis Dataset
Overview
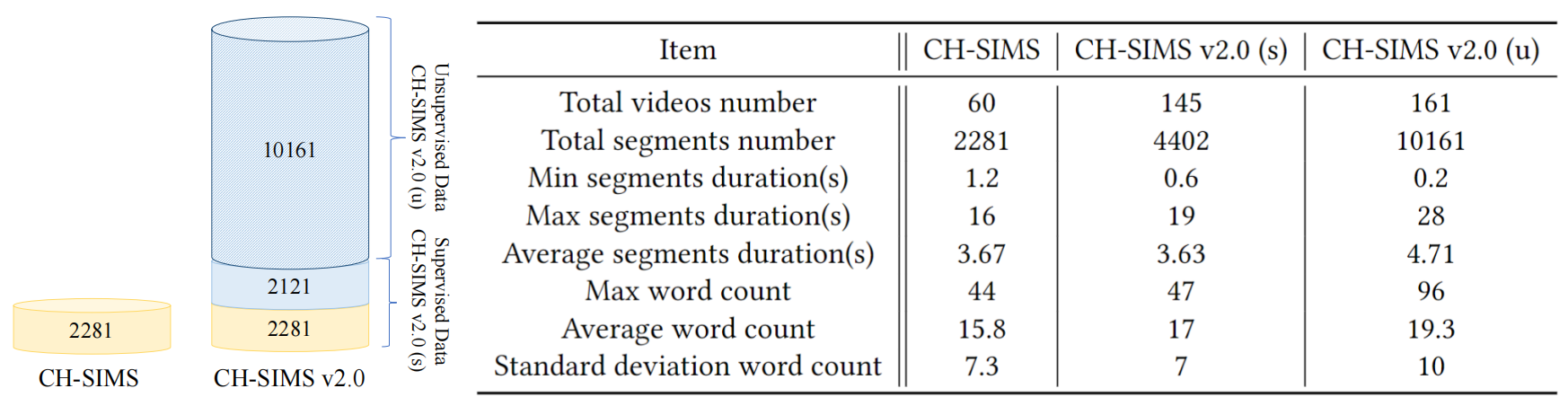
CH-SIMS v2.0, a Fine-grained Multi-label Chinese Sentiment Analysis Dataset, is an enhanced and extended version of CH-SIMS Dataset. We re-labeled all instances in CH-SIMS to a finer granularity and the video clips as well as pre-extracted features are remade. We also extended the number of instances to a total of 14563. The new dataset contains videos collected from much wider scenarios, as shown in the banner image.
As shown in below figure, CH-SIMS v2.0 contains 4402 supervised instances, denoted as CH-SIMS v2.0 (s), and 10161 unsupervised instances, denoted as CH-SIMS v2.0 (u). The supervised instances share similar properties with CH-SIMS dataset. The unsupervised instances show a much more diverse distribution of video duration, which better simulates real-world scenarios. The textual features of the unsupervised instances are collected from the ASR transcript without manual correction and thus contain noise, which also fits real-world scenarios better.
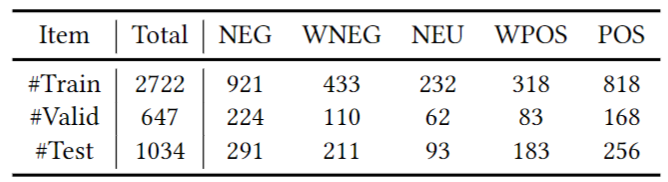
We split train, valid and test set to a proportion of roughly 9:2:3. The regression labels range from -1 to 1. The classification labels are: Negative(NEG), Weakly Negative(WNEG), Neutral(NEU), Weakly Positive(WPOS), and Positive(POS). The label distribution is shown in below figure. The test set is speaker-unrelated with the train/valid set.
The baseline experiments are conducted via MMSA platform. The results are reported HERE on Github.