Abstract
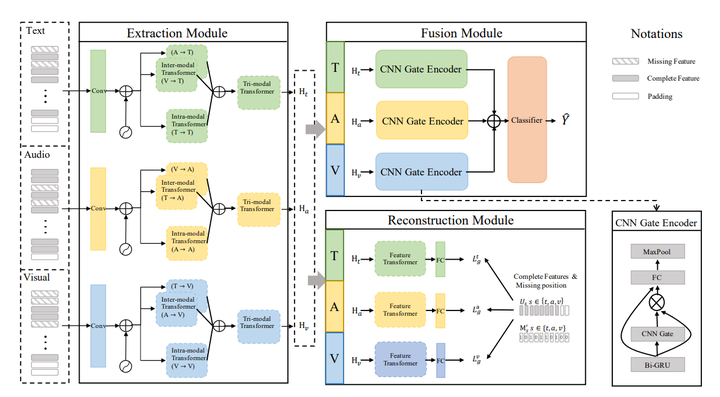
Improving robustness against data missing has become one of the core challenges in Multimodal Sentiment Analysis (MSA), which aims to judge speaker sentiments from the language, visual, and acoustic signals. In the current research, translation-based methods and tensor regularization methods are proposed for MSA with incomplete modality features. However, both of them fail to cope with random modality feature missing in non-aligned sequences. In this paper, a transformer-based feature reconstruction network (TFR-Net) is proposed to improve the robustness of models for the random missing in non-aligned modality sequences. First, intramodal and inter-modal attention-based extractors are adopted to learn robust representations for each element in modality sequences. Then, a reconstruction module is proposed to generate the missing modality features. With the supervision of SmoothL1Loss between generated and complete sequences, TFR-Net is expected to learn semantic-level features corresponding to missing features. Extensive experiments on two public benchmark datasets show that our model achieves good results against data missing across various missing modality combinations and various missing degrees.