Abstract
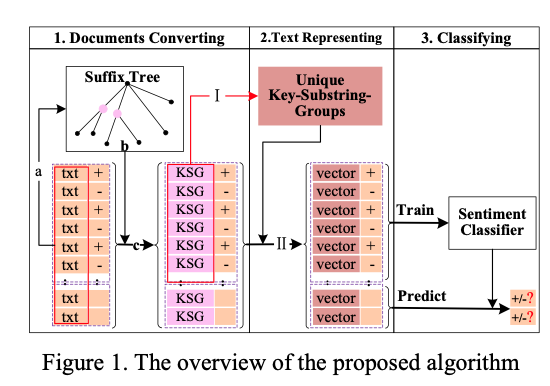
One of the most widely-studied sub-problems of opinion mining is sentiment classification, which classifies evaluative texts as positive or negative to help people automatically identify the viewpoints underlying the online user-generated information. Most of the existing methods for sentiment classification ignore word sequence and unlabeled test documents' structural information. This paper proposes a transductive learning based algorithm considering both of these two types of information. The proposed algorithm is implemented by firstly selecting key substrings in the suffix tree constructed from the strings in training and unlabeled test documents and then converting each original text document to a bag of numbers of the key substrings. Finally, SVM is employed to classify the converted documents. Experiments on the open dataset (16,000 Chinese reviews) demonstrate promising performance of the proposed algorithm, the accuracy being over 93.15%, which is much better than the performance of the existing sentiment classification methods, such as n-gram features based classification algorithms. Experimental results also show that “tfidf-c” performs much better than other term weighting approaches in sentiment classification for large text corpus. In particular, the reasons behind the proposed algorithm’s outstanding performance are further studied and analyzed in this paper. Moreover, the proposed algorithm can avoid the messy and rather artificial problem of defining word boundaries in Chinese language.