Abstract
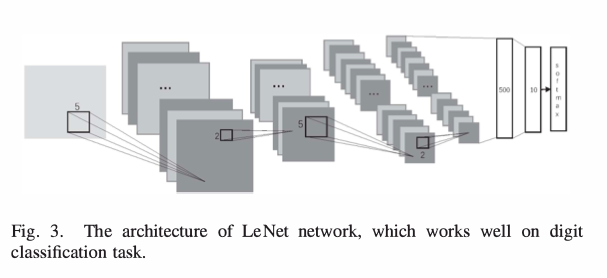
Recently, rectified linear units (ReLUs) have been used to solve the vanishing gradient problem. Their use has led to state-of-the-art results in various problems such as image classification. In this paper, we propose the hyperbolic linear units (HLUs) which not only speed up learning process in deep convolutional neural networks but also obtain better performance in image classification tasks. Unlike ReLUs, HLUs have inheriently negative values which could make mean unit outputs closer to zero. Mean unit outputs close to zero means we can speed up the learning process because they bring the normal gradient close to the natural gradient. Indeed, the difference called bias shift between natural gradient and the normal gradient is related to the mean activation of input units. Experiments with three popular CNN architectures, LeNet, Inception network and ResNet on various benchmarks including MNIST, CIFAR-10 and CIFAR-100 demonstrate that our proposed HLUs achieve significant improvement compared to other commonly used activation functions1.