An Empirical Study of Emotion Analysis with Different Distributed Representation Methods for Chinese Microblogs
Abstract
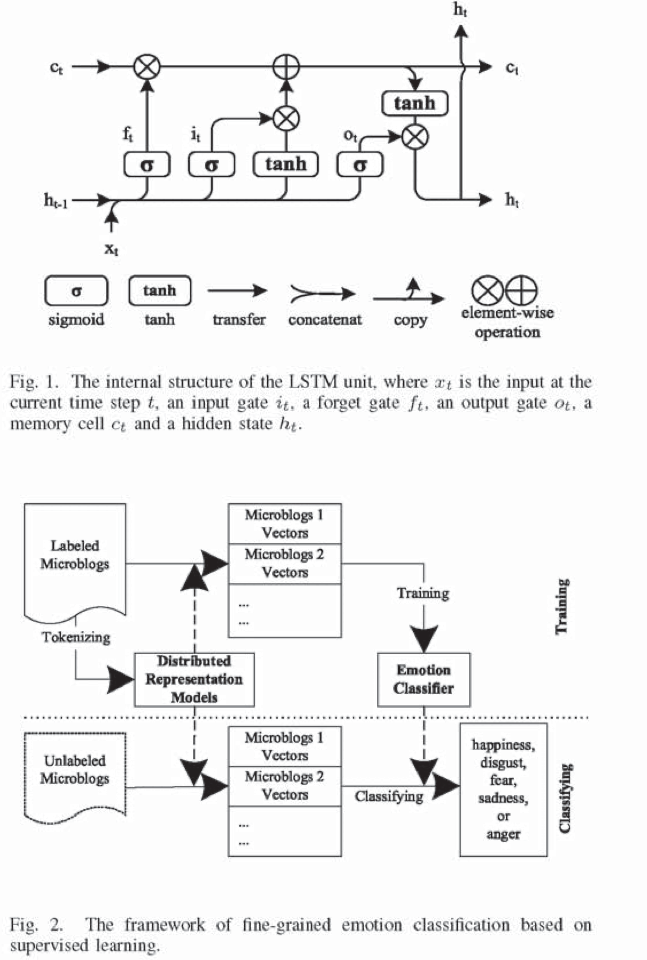
Distributed representation of text has the ability to effectively express the meaning of text. Up to now, most studies have adopted distributed representation methods for emotion analysis on Chinese microblogs without systematically comparing and analyzing the performance of them with different parameters. This paper conducts an empirical study for fine-grained emotion categorization on Chinese microblogs. Firstly, we collect a labeled corpus. It is processed into four types of experimental dataset based on different text granularity, i.e., the sentence-level dataset with characters (SLwC), the sentence-level dataset with words (SLwW), the paragraph-level dataset with characters (PLdC) and the paragraph-level dataset with words (PLdW). Secondly, five models of distributed representation (the average of word vectors, PV-DM, PV-CBOW, LSTM, and BiLSTM) are chosen. These methods are compared on the above four types of experimental datasets respectively. Finally, support vector machine (SVM) acts as an additional classifier to correctly classify users’ emotions in microblogs. The results indicate: 1) BiLSTM performs the best for generating emotional feature representation. Moreover, it performs the best on the paragraph-level dataset by combining with SVM; 2) Five models achieves better performance on paragraph-level dataset for emotion classification than sentence-level dataset whereas words as tokens of text are superior to those of characters 3) All models get better performance while the dimension of words between 300 with 500, especially for the LSTM-based with SVM methods.